
Years ago, pestilence I read a post by the always-awesome Eric Ries called “The one line split-test, or how to do A/B all the time” and I thought it was brilliant. He espoused that with a low enough setup-cost, A/B testing could be used prolifically.
A while later, I was involved in writing an A/B Testing framework at Wikia (Fandom) and we were able to create a fairly simple system which allowed Product Managers to create and view experiments easily from a panel. However, due to the type of site Wikia is, each experiment often wanted to track different metrics.
You may be expecting what comes next: the small amount of friction required from both a Product Manager to set up an experiment, and the extra friction of figuring out how to get custom metrics… lead to this rather-advanced* system being used very-little in practice.
Recently, due to the success of Burndown for Trello, I’ve been wanting to leverage the size of our user-base to use A/B testing that will let us make more data-driven design decisions. I re-visited Eric Ries’s post and was reminded of my past experiences that even the smallest amount of friction can prevent A/B testing from being used prolifically. I thought it would be great if there was a library to do that one-line testing… and if the library itself was so easy to set up that it would provide very little friction for projects to integrate it and get started.
So, I created LeanAb. It’s free, open source, and takes about 15 minutes to set up the first time and get to running an experiment. To be blunt, even if nobody else uses it, I’ll be happy to have it around so that I can continue to drop it into my various sites… but I think that if you’re considering split-testing on your site and have been putting it off, this could quite likely be a great help for your projects.
Here were my goals for the first version of LeanAb, all of which have been reached:
- Have it be very simple one-line calls like those mentioned in the Eric Ries article
- Self-contained to one file
- Fast/Easy to set up
- Self-installs the needed database schema
- Ability to generate basic reports easily (eg: one line of code, or using the very basic report page provided in the repository)
- Fail gracefully so that regardless of errors, the worst that happens is that nothing experiment-related gets written to database, and user sees control group.
Usage is as simple as this:
$hypothesis = setup_experiment("FancyNewDesign1.2",
array(array("control", 50),
array("design1", 50)));
if( $hypothesis == "control" ) {
// do it the old way
} elseif( $hypothesis == "design1" ) {
// do it the fancy new way
}
The reports that it generates automatically look something like this:
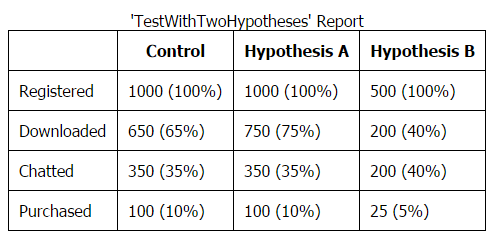
If you’re interested, head over to the Lean AB github page to try it out, or follow to its ongoing development. Full installation/usage documentation is provided in the README on github.
If you use this in your project, please let me know in the comments below!
Hope that helps,
– Sean
*: the advanced parts were mostly hidden from end-users. It ran extremely fast even though the site served over a billion pages per day. It was also designed to allow either the server code or the front-end code to easily access a user’s treatment-group, possibly for several experiments per-page, all with no perceptible impact on performance.